To use SQL as a data source you have to do the following steps:
Create a new source application in the flex.bi source application tab.
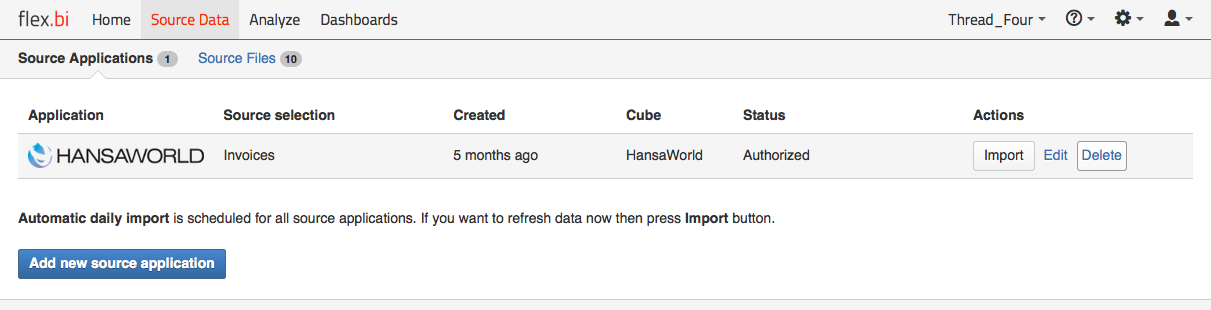
Make sure you select SQL as your data source when creating a new source application
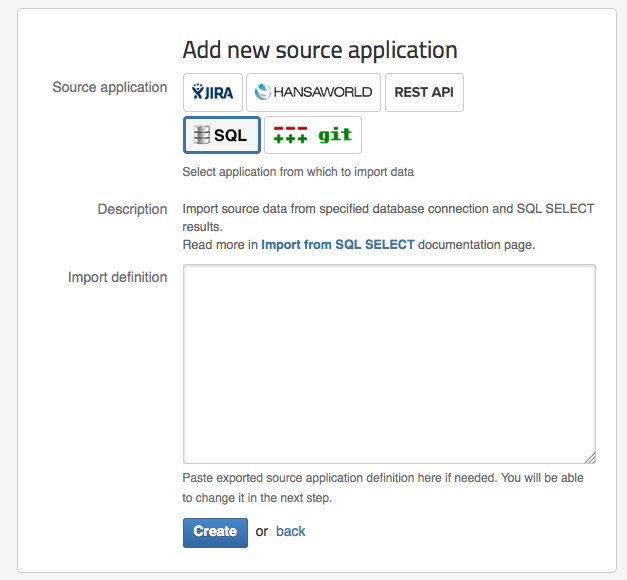
If you have created already another similar SQL data source then you can export its definition and paste it in Import definition to create new SQL source application with the same parameters.
SQL source parameters
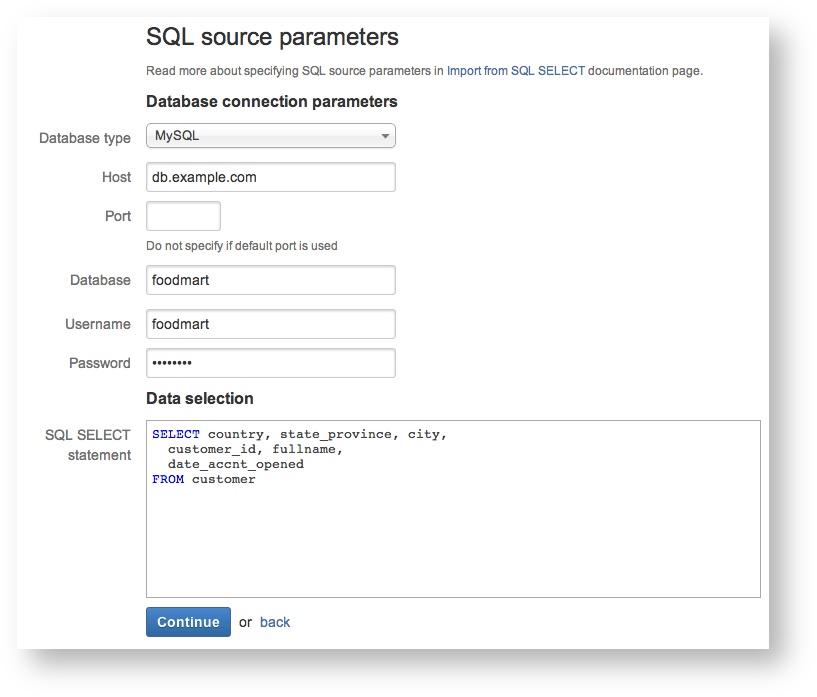
For the following fields provide the information required:
Database type
Select the database type from the list of available options.
Host
Write the host IP of your selected database type.
Port
Write the port number your database uses, if you are using the default port for your selected database then you can leave this blank.
Database
Write your database name.
Username
Write the username of the user you wish to use to connect to the database.
Password
Write the password of the user you are using to connect to the database.
SQL SELECT statement
Write an SQL statement that will be used to retrieve data from the database. The SELECT part of the SQL statement determines the columns you will have to map in the next step.
Source column mapping
Once you have finished setting your parameters you will have to conduct the Source column mapping.

Mapping the data to columns is similar to importing excel and CSV files. The differences here are that you need to name your own cube and dimensions, because they need to be created if your data does not fit any of the already existing cubes.
When you need to import several columns as the same dimension attributes then click Show options and specify the following options:
- ID column - if attribute is unique integer ID attribute of dimension member. If ID column is not specified then dimension members will be identified by key column and IDs will be automatically generated for each new key column value.
- Key column - if attribute is unique numeric or string key of dimension member (like issue
numberhere) - Name column - if attribute is longer name that should be displayed as dimension member name (if not specified then key column will be used as name column). But keep in mind that name column still needs to be unique within dimension (therefore in this case we will not use
titleas name as it might not be unique). - Ordinal column - if this attribute should be used to order dimension members.
- Property name - specify if attribute should be imported as additional property for dimension member which is identified by ID or key column.
- When importing date or datetime field as dimension property you can specify additional options:
- Date count measure - specify measure name that should store count of imported rows in this date.
- Date count dimension - specify time dimension which should be used for this measure (by default
Timedimension name is suggested).
When you are finished mapping your data press the Start Import button.
If your import finishes successfully you can see the results in the Analyze tab in the cube you imported your data to.