Support center for flex.bi version 4.0
REST API (non-HansaWorld app)
- Laima (Deactivated)
- Gvido
- Inta (Deactivated)
To use REST API as a data source you have to do the following steps:
Create a new source application in the flex.bi source application tab.
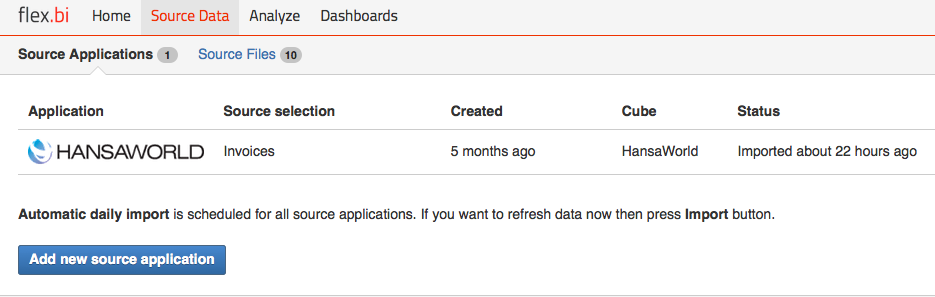
Make sure you select REST API as your data source when creating a new source application
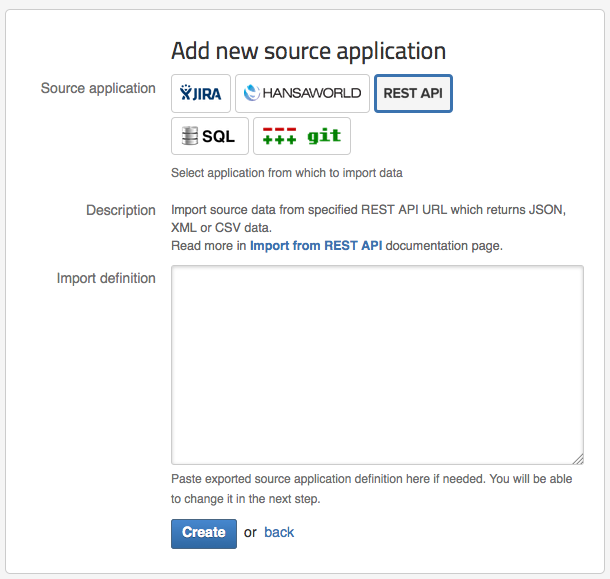
If you have created already another similar REST API data source then you can export its definition and paste it in Import definition to create new REST API source application with the same parameters.
REST API source parameters
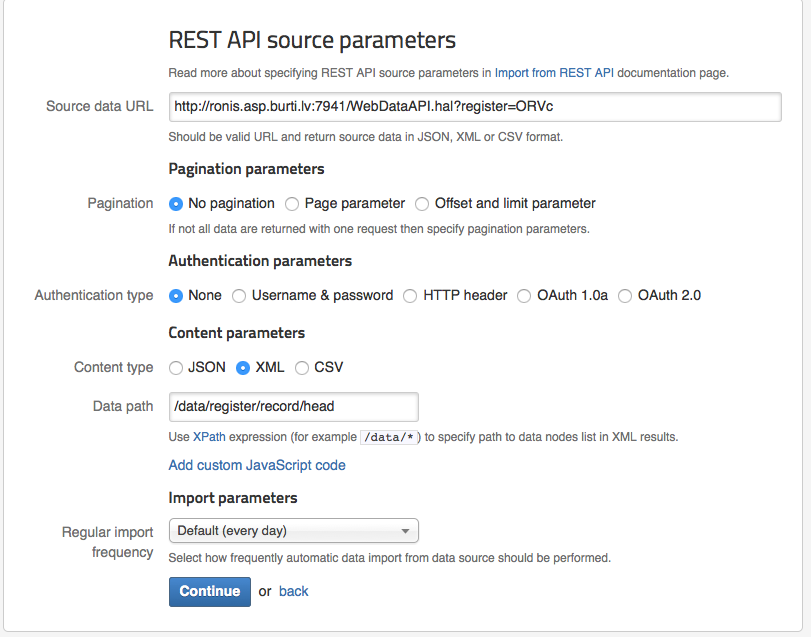
For the following fields provide the information required:
Source data URL
For the source data URL enter the REST API URL which returns data and all the parameters that are needed for your data.
Pagination parameters
Specify if you the REST API request can return all the data with a single request, otherwise you must specify the page parameter or offset and limit parameter.
Use Page parameter if you want to return pages of data. You have to specify the name of the page parameter REST API should use to return paginated data.
If you want to return a certain amount of data use Offset and limit. The limit tells REST API how many records to return and offset tells REST API from which record it should start getting the data. If offset is est to 20 and the limit to 30, REST API will return records from 20-50
It is recommended to use page or offset and limit parameters if possible as it will enable concurrent REST API requests and will make the import faster. By default, up to 10 concurrent REST API requests will be made at the same time. Starting from the flex.bi version 4.3.0 you can adjust the maximum number of concurrent requests using the Concurrency parameter (for example, reduce it if too many concurrent requests are causing errors in the source application).
Authentication parameters
Select the type of authentication you are using and enter all the values that are required for it.
Incremental import
Available from flex.bi version 4.2.
By default, REST API import will always re-import all data. During the import the old imported data will be deleted and then replaced by new returned data. If REST API returns many pages of results then each data import might take long time as well as reports might return incomplete data while the old data are deleted and not all new data are imported.
If REST API supports additional parameters to return just the recently updated data then you can use the incremental import option to update just the recent source data after the initial full import. Click Incremental import parameters to specify additional parameters:
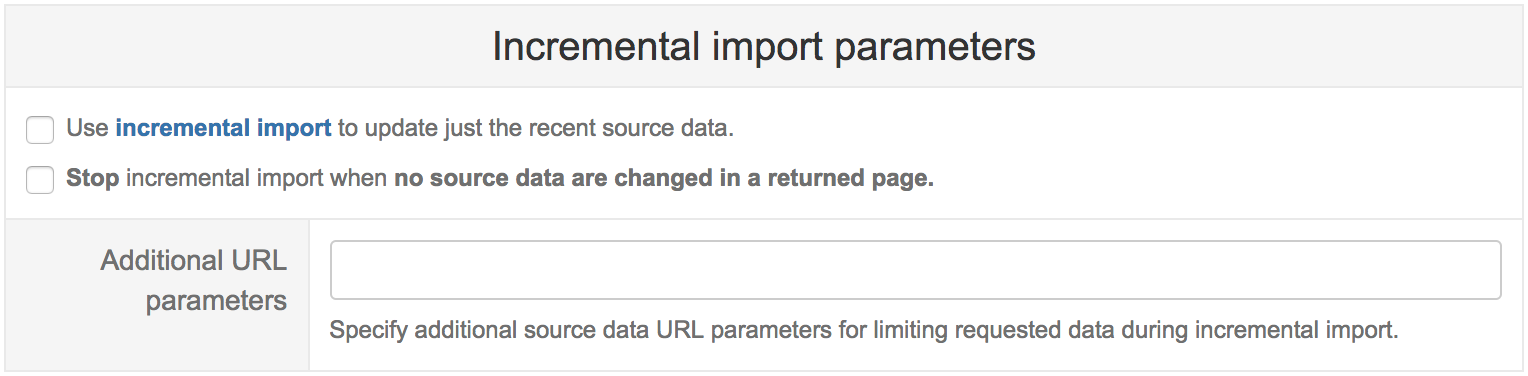
- Select Use incremental import to enable it.
- If REST API does not provide parameters for selecting just the recent updated data then you can use the option "Stop incremental import when no source data are changed in a returned page". If during the import some REST API results page will have all the same data that have been imported before then the import will be stopped. But, please, be aware that if data are changed when stored in flex.bi (e.g. decimal numbers are truncated when stored), then the source data page will not be exactly the same as in flex.bi.
Therefore it is recommended to specify Additional URL parameters to limit just the recently updated source data. Typically you need to specify a URL date parameter that limits results to recently updated source data.
For example, in our GitHub issues example REST API hassinceparameter to return only issues updated at or after the specified date and time. We can use the following additional URL parameter:
since={{ 3 days ago | %Y-%m-%d }}This will dynamically get a relative date and time 3 days ago and will format it using a strftime format string %Y-%m-%d (see available strftime format options). The following relative time units can be used – years, months, weeks, days, hours, minutes, seconds. And instead of ago also from now can be used to get a date and time in future.
If incremental import is used then it will be required to specify a Source ID column in the source columns mapping step. Source ID column value should provide a unique results row identifier. It is used to identify when some existing imported rows in flex.bi should be replaced with updated source data during the incremental import.
If you have previously imported all data without the incremental import option, then it will not be possible to modify the source columns mapping. Therefore, at first delete all imported data for this REST API source, and then modify the source columns mapping and specify the Source ID column.
If REST API does not return a column that could be used as a unique Source ID column, then you can use a custom JavaScript code to create a new doc property that could be used as a unique identifier – e.g. concatenate values of several other properties that will create a unique identifier for a row.
Content parameters
Select the kind of data your REST API request will return. Your choices are JSON, XML or CSV.
You can also add custom JavaScript code if you chose JSON as your content parameter.
Custom JavaScript code
You can use custom JavaScript code to modify received JSON, XML or CSV data before importing into flex.bi. Click Add custom JavaScript code to show code editor.
You can use doc variable to access received data object properties and modify or add additional properties. If necessary you can define additional JavaScript functions that you need to use in your code.
Here is example of JavaScript code which will change title property to capitalized version (first capital letter and then lowercase letters):
function capitalize(s) { return s.charAt( 0 ).toUpperCase() + s.slice( 1 ).toLowerCase();}doc.title = capitalize(doc.title); |
If you would like to skip some data rows and do not import them in flex.bi then use return false; in these cases. Here is example which will skip data rows which do not have title property:
if (!doc.title) return false ; |
You can also create new properties for doc object when you need to construct flex.bi dimension level names or calculate additional measures. Here is example how to create full_name property:
doc.full_name = doc.first_name + " " + doc.last_name; |
Import parameters
Select the frequency of the data import. An automatic import will be started every time the specified amount of time passes.
Source column mapping
To conduct the Source column mapping please visit Data mapping .
When you have finished mapping your data press 'Start Import' button.
If your import finishes successfully, you can see the results in the Analyze tab in the cube you imported your data to.